Creating DSLs with Frag: Parser and Mapping Specification
To support the external DSL option, too, FMF models can be created using any parser. For instance,
all kinds of parser generators or XML parsers could be used to create external concrete syntaxes
for FMF models. In addition, in Frag, we propose a lexical parsing approach based on the composition of
rule definitions that are similar to EBNF.
To work with the lexical parser framework, you must first import it:
import frag.parser.LexicalParsing
Now you can access an object, called Parser in the LexicalParsing namespace. It allows you to
create new lexical parsers within Frag.
- setRules <rules>: Set the lexical parsing rules for this parser.
- getRules: Get the lexical parsing rules defined for this parser.
- apply <source>: Apply the parser for the given source text.
A rule is basically a description of the situation when the rule matches (a matcher) plus an action
that is taken when the rule applies. Basically, the Frag lexical parser walks through the source code, and, for each rule, if
a matcher matches, its action is triggered.
The result is a tokenized list of parsed elements. List elements can also contain
information, which must be further parsed. So the resulting parsed elements list roughly corresponds to an AST in other parsing
approaches. In our experience so far this approach is well suited for rapid prototyping of parsers and
incremental development, i.e., it supports stepwise improving the external syntax of a DSL.
For specifying lexical parsing rules we have defined a DSL with a syntax close to EBNF. In it, a rule definition has the format:
<ruleSymbol> <matcherSpecification> ?token?;
That is, all
rule specifications start with the rule symbol %. Which action is taken is determined by one of the forms that the rule symbol
% can take:
- %: If the matcher matches, the parsed element is append without changes to the parsed elements list.
- %-: If the matcher matches, the parsed element is ignored.
- %(<leftTrim>,<rightTrim>: If the matcher matches, the parsed element is append
to the parsed elements list. It is trimmed on the left hand side by <leftTrim> characters, and on the
right hand side by <rightTrim> characters. Both <leftTrim> and <rightTrim> must be
positive or zero integer values.
The matcher specification describes the elements that are matched by this rule. It might contain combinations of the following symbols:
- "<literal>": literal will be matched. You can use backslash sequences inside of literal.
- ?: Any single character will be matched.
- <element1> <element2>: A sequence of two elements will be matched.
- ( <elements> ): A grouping of elements will be matched.
- !<element>: A character will be matched, if it does not start with the element.
- <element1> | <element2>: Two elements are alternatives, and either of them will be matched.
- <element>[<from>..<to>]: The element is matched, if it occurs in a repetition from from to to times.
from must be an integer that is zero or positive.
to must be either an integer that is zero or positive, or * for any maximum number of elements.
Instead of <from>..<to> you can also just specify * to indicate any number of elements.
- {<chars>}: Any single char in chars will be matched. You can use backslash sequences inside of chars.
The last element of a rule definition is the token. The token is optional. It is a literal (a string) that is set on the
element in the parsed elements list, if the rule matches. The token can be used to later identify which rule has created the
parsed element. If the token is not specified, the token of the element is an empty string.
In addition to rules, you can also define matcher variables, containing a matcher specification that can be used
in one or more rules using the ID (name) of the matcher variable. This way reuse of matcher specifications in more than one
rule definition is possible. The matcher variable IDs can hence also be used as part of rule definitions.
The syntax for matcher variables is:
<matcherVariableID> = <matcherSpecification>;
To illustrate the use of lexical parsers, consider the following simple example: We want to parse lists of words,
and ignore all whitespaces between them. Hence, we first need to define the char set for whitespaces. We do this in
the matcher variable WS to reuse it later in two rules. The first rule (%- WS;) ignores all whitespaces. The
second rule matches everything that is more than one character long and not a whitespace. Everything that is matched by
this rule is added to the parsed elements list as a new element with the token WORD:
LexicalParsing::Parser create p1
p1 setRules [string build `
WS = { \t\r\n};
%- WS;
% (!WS)[1..*] "WORD";
`]
To use this rule, we need to call the method apply of the parser. For example:
p1 apply `abc 123 5 6 7`
will create the following list of elements, all having the token WORD:
abc 123 5 6 7
Consider now we want to extend our example to support curly braces blocks in which whitespaces might occur.
A simple way to define such blocks is:
LexicalParsing::Parser create p1
p1 setRules [string build `
WS = { \t\r\n};
RESERVED = (WS | {{});
BLOCK = "{" (!"}")[*] "}";
%- WS;
% BLOCK "BLOCK";
% (!RESERVED)[1..*] "WORD";
`]
set result [p1 apply `abc {1 2 3} {5 6} 7`]
The result of applying the parser is the following list of elements: abc {{1 2 3}} {{5 6}} 7.
The first and the last elements of this list have the token WORD, the two inner elements have the token BLOCK.
In this result we might be unhappy with the fact that the block delimiters are added as list elements.
As they are of the fixed size 1, we can trim them directly in the parser by using a trimming action on the
BLOCK rule:
%(1,1) BLOCK "BLOCK";
This cuts one character at the beginning and end of each block. Hence the resulting list would change to:
abc {1 2 3} {5 6} 7.
One problem in our example is that blocks cannot yet contain the character "}" which ends the block. We
can introduce the possibility to use backslashes in blocks in order to avoid this.
LexicalParsing::Parser create p1
p1 setRules [string build `
WS = { \t\r\n};
RESERVED = (WS | {{});
BACKSLASH = "\\" ?;
BLOCK = "{" (BACKSLASH | (!"}"))[*] "}";
%- WS;
%(1,1) BLOCK "BLOCK";
% (!RESERVED)[1..*] "WORD";
`]
set result [p1 apply `abc {1 2 3} {5 6} 7`]
If we now apply the parser for: p1 apply `abc {1 t}} {5 6} 7` we get the result: abc {1 t}} {5 6} 7.
Finally, we might only want to support well-formed blocks. That is, a block is only recognized as a block, if nested
blocks are correct blocks as well. That is, if a block contains a "{" or a }" character without the other, an error should
be raised. This can be reached by defining the BLOCK recursively, as follows:
BLOCK_ELEMENT = (BACKSLASH | (!{\{\}}))[1..*];
BLOCK = "{" (BLOCK | BLOCK_ELEMENT)[*] "}";
Here, the block element contains either backshlashed elements or elements that are not "{" or }". A block can contain other
blocks or block elements. If we parse the well-formed structure: p1 apply `abc {1 {2 3} 3 4} {5 6} 7`, we get the result:
abc {1 {2 3} 3 4} {5 6} 7.
Please note that in this example, the inner block is not yet parsed up and tokenized. The list 1 {2 3} 3 4 is given to
the parsed element as is, and can later be further parsed up using this or another lexical parser,
as defined by a mapping (see below).
To ease mapping the parsed elements lists to the language model, we provide a mapping DSL. It basically
can map elements, sequences of elements, alternatives, and repetitions in the parsed elements lists to
Frag objects. In particular, it can be used to trigger code fragments that create and fill instances
of the language model with the parsed information.
In order to use the mapping DSL, you must import the package mdd.DSL:
import mdd.DSL
The following code shows a simple DSL mapping for the parser defined above.
We assume that the result is parsed into a parsed elements list with the tokens
BLOCK and WORD, using the following lexical parser:
LexicalParsing::Parser create textCommandParser
textCommandParser setRules [string build `
WS = { \t\r\n};
RESERVED = (WS | {<>});
BACKSLASH = "\\" ?;
WORD = (BACKSLASH | !RESERVED)[1..*];
BLOCK = "<" (WORD|WS)[*] ">";
%- WS;
%(1,1) BLOCK "BLOCK";
% WORD "WORD";
`]
The following mapping specification accepts any repetition
of a sequence of two elements, where the first element has the token BLOCK and the second element
is any repetition of one or more WORDs. Before the outer repetition is mapped, we add
Mapping Results: to the result. Each time the sequence is mapped, a variable text is initialized.
It is filled by the inner repetition with a list of words. Before the words are parsed, we expect
an element with the token BLOCK, which is mapped to the variable command. Finally, for each sequence,
the command and its text are add to the result. At the end of the entire mapping, the result is read, so that
any invocation of the mapping returns the result.
DSL::DSLMapping create TextCommandMapping -mapping {
@rep * {
@seq {
@elt command {$token == BLOCK}
@rep 1..* {
@elt word {$token == WORD} {append text $word}
}
} {set text ""} {append result "Command = $command, Text = $text"}
} {set result "Mapping Results:"} {get result}
}
A mapping can be executed using the map method. For example, we could execute
the mapping for the parse result of the input parsed below:
set parseResult [textCommandParser apply {
<text plain>
a text
<text bold>
a bold text
}]
TextCommandMapping map $parseResult
The result is:
Mapping Results: {Command = text plain, Text = a text} {Command = text bold, Text = a bold text}
The following mapping specification language elements are predefined in the parser mapping DSL:
- @elt ?ID? ?checkCondition? ?mappingCode?: A single element that does not violate
the checkCondition must occur next in the parsed elements list. If this is the
case, the mappingCode is executed, and in it a variable with the value of ID
is set to the content of the parsed element. The checkCondition is a Frag expression. If a
token has been set on the element that is checked, the variable token is set to its
token value. If an ID is given, a variable with the name of the ID is set to the value
of the element that is checked.
- @seq <mappings> ?beforeCode? ?afterCode?: The sequence of given mappings
must occur next in the parsed elements list. Before mapping the sequence, beforeCode
is executed, and after the mapping afterCode.
- @alt <mappings> ?beforeCode? ?afterCode?: One of the given mappings must occur
next in the parsed elements list. Before mapping the alternatives, beforeCode is executed,
and after the mapping afterCode.
- @rep <multiplicity> <mapping> ?beforeCode? ?afterCode?: A repetition of
multiplicity times of the given mapping must occur next in the parsed elements list.
Before mapping the repetition, beforeCode is executed,
and after the mapping afterCode.
The flexibility of parsing and mapping specifications has a number of benefits:
We can easily change and update parser definitions to be able to later decide on how to integrate
different DSLs. Syntax extensions can be defined at any stage of DSL development easily.
Finally, in many parsing approaches it is rather cumbersome to deal with custom error messages.
In Frag, custom error messages are easily introduced, as all parser parts (rule and mapping elements)
are ordinary Frag objects that can throw Frag exceptions.
In this section, we illustrate the parsing and mapping appraoch, as well as defining a corresponding language model,
using Fowler's introductory example. The example is about describing
state machines used to implement machinery to lock and unlock secret compartments. The next figure shows a sample state machine
presented by Fowler: Miss Grant's system. She has a secret compartment in her bedroom that is normally locked and concealed.
To unlocked it for her to open, she has to close the door, open a draw in her chest, and turn a light on.
Many variations of the sequence of actions that can be carried out and the resulting behavior of the controller software exist.
The example DSL should support the company, providing the controllers, so that they can install a new system with minimal effort.
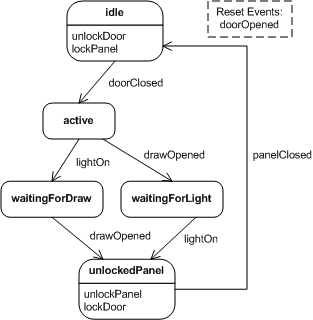 To model state charts as the one in the figure above using the DSL, we need to be able to declare events, commands, states, and
transitions between states. States contain references to actions, which should be executed when entering the state. The
transitions are triggered by events, and link between a source and target state. The first step to realize this DSL
in Frag is to design and implement the language model of the DSL. The figure below shows a language model that we have derived and
adapted from Fowler's example.
To model state charts as the one in the figure above using the DSL, we need to be able to declare events, commands, states, and
transitions between states. States contain references to actions, which should be executed when entering the state. The
transitions are triggered by events, and link between a source and target state. The first step to realize this DSL
in Frag is to design and implement the language model of the DSL. The figure below shows a language model that we have derived and
adapted from Fowler's example.
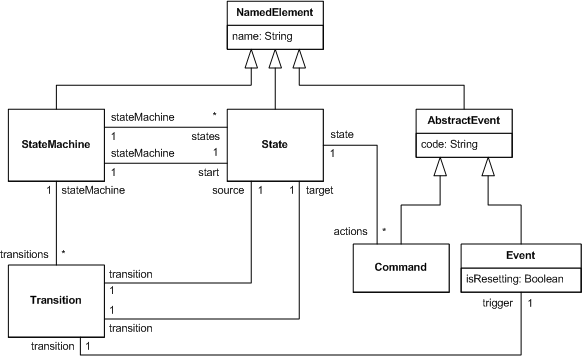 We use FMF to implement the model in Frag. The code below shows the language model implementation for the example.
Various classes and associations between these classes, following the design in the figure above, are defined. We use
object names to denote identifiers for states, events, and commands. Hence, we do not need to implement
the NamedElement class. The isResetting property is defined with false as a default value, as most
events are not resetting. Apart from these two implementation details, the Frag implementation corresponds
exactly to the figure.
We use FMF to implement the model in Frag. The code below shows the language model implementation for the example.
Various classes and associations between these classes, following the design in the figure above, are defined. We use
object names to denote identifiers for states, events, and commands. Hence, we do not need to implement
the NamedElement class. The isResetting property is defined with false as a default value, as most
events are not resetting. Apart from these two implementation details, the Frag implementation corresponds
exactly to the figure.
FMF::Class create StateMachine
FMF::Class create State
FMF::Association create StateMachineStates -ends {
{StateMachine -roleName stateMachine -multiplicity 1 -navigable true}
{State -roleName states -multiplicity * -navigable true}
}
FMF::Association create StateMachineStart -ends {
{StateMachine -roleName stateMachine -multiplicity 1 -navigable true}
{State -roleName start -multiplicity 1 -navigable true}
}
FMF::Class create Transition
FMF::Association create StateMachineTransitions -ends {
{StateMachine -roleName stateMachine -multiplicity 1 -navigable true}
{Transition -roleName transitions -multiplicity * -navigable true}
}
FMF::Association create TransitionSource -ends {
{Transition -roleName transition -multiplicity 1 -navigable true}
{State -roleName source -multiplicity 1 -navigable true}
}
FMF::Association create TransitionTarget -ends {
{Transition -roleName transition -multiplicity 1 -navigable true}
{State -roleName target -multiplicity 1 -navigable true}
}
FMF::Class create AbstractEvent -attributes {
code String
}
FMF::Class create Event -superclasses AbstractEvent -attributes {
isResetting boolean
}
Event method init args {
self isResetting false
}
FMF::Class create Command -superclasses AbstractEvent
FMF::Association create StateCommand -ends {
{State -roleName state -multiplicity 1 -navigable true}
{Command -roleName actions -multiplicity * -navigable true}
}
FMF::Association create TransitionTriggerEvent -ends {
{Transition -roleName transition -multiplicity 1 -navigable true}
{Event -roleName trigger -multiplicity 1 -navigable true}
}
Once a language model is defined, we can use the Frag syntax to create instances of the model. That is, by defining the
language model, we automatically have a rich embedded Frag syntax that can be used. This syntax is the same syntax as for
defining the language model. The code below shows an example in which we create a model instance that implements the state
chart from the state machine in the figure above.
Event create doorClosed -code D1CL
Event create drawOpened -code D2OP
Event create lightOn -code L1ON
Event create doorOpened -code D1OP -isResetting true
Event create panelClosed -code PNCL
Command create unlockPanel -code PNUL
Command create lockPanel -code PNLK
Command create lockDoor -code D1LK
Command create unlockDoor -code D1UL
StateMachine create MissGrantsSystem -states [list build
[State create idle -actions {unlockDoor lockPanel}]
[State create active]
[State create waitingForLight]
[State create waitingForDraw]
[State create unlockedPanel -actions {unlockPanel lockDoor}]
] -transitions [list build
[Transition create -source idle -target active -trigger doorClosed]
[Transition create -source active -target waitingForLight -trigger drawOpened]
[Transition create -source active -target waitingForDraw -trigger lightOn]
[Transition create -source waitingForLight -target unlockedPanel -trigger lightOn]
[Transition create -source waitingForDraw -target unlockedPanel -trigger drawOpened]
[Transition create -source unlockedPanel -target idle -trigger panelClosed]
] -start idle
This example uses the Frag syntax in a pretty plain way. Actually, only two language features
of Frag that are not derived from the language model are used. Firstly, we use list build
to pass lists to the state machine instance. Secondly, we use unnamed objects for transitions.
Both features are used to simplify the code and do not have to be used. However, we can also
go much further, and use all kinds of language constructs defined in Frag. For instance, the
code below shows a foreach loop doing the same as the Command and Event instantiations above. This syntax
would be useful, if some additional tasks must be performed for each object that is instantiated.
foreach {eventName code} {
doorClosed D1CL
drawOpened D2OP
lightOn L1ON
doorOpened D1OP
panelClosed PNCL
} {
Event create $eventName -code $code
}
doorOpened isResetting true
foreach {cmdName code} {
unlockPanel PNUL
lockPanel PNLK
lockDoor D1LK
unlockDoor D1UL
} {
Command create $cmdName -code $code
}
The two examples show the benefits and liabilities of embedded DSL syntaxes. As a benefit, we can use the Frag
language features for simplifying and shortening the code. We can use features, such as control structures
and substitutions, to ease (recurring) tasks. Software developers will appreciate such features being available,
as they allow them to automate tasks and make the code more readable. However, as a liability the user of the
DSL must understand the Frag features. Even if users use only a limited subset of Frag, they must be aware that
they are using an embedded DSL. For non-technical users there is the danger that they accidentally use Frag
features and/or get hard to understand error messages.
One benefit of the Frag approach is that we can first start-off by defining an embedded DSL, which is
useful for developing, testing, and evolving the language model, and then add the external DSL artifacts.
Consider we want to make the example DSL be usable for non-technical stakeholders later on in our project.
Fowler suggests the external syntax for the DSL that is shown below.
events
doorClosed D1CL
drawOpened D2OP
lightOn L1ON
doorOpened D1OP
panelClosed PNCL
end
resetEvents
doorOpened
end
commands
unlockPanel PNUL
lockPanel PNLK
lockDoor D1LK
unlockDoor D1UL
end
state idle
actions {unlockDoor lockPanel}
doorClosed => active
end
state active
drawOpened => waitingForLight
lightOn => waitingForDraw
end
state waitingForLight
lightOn => unlockedPanel
end
state waitingForDraw
drawOpened => unlockedPanel
end
state unlockedPanel
actions {unlockPanel lockDoor}
panelClosed => idle
end
The syntax above might be quite readable for non-technical stakeholders, but it includes a few
challenges. For example, it is not clear what should happen, if end or one of the other keywords (state, events, ...)
needs to be used inside
a block (e.g., if an event is named end). We decided that curly braces must be used around it the keyword
if this is wanted, as curly braces are already used in the syntax for actions. Hence, we decided to let the parser only
search for the keywords, curly braces blocks, and words. The structure is defined via the DSL mapping later. The
result is a simple parser specification:
LexicalParsing::Parser create statemachineParser
statemachineParser setRules [string build `
WS = " " | "\r\n" | "\n" | "\t";
WORD = (! (WS | "{" | "}"))[1..*];
%- WS;
%(1,1) ("{" (WORD | WS)[*] "}") "BLOCK";
% "=>" "ARROW";
% WORD "WORD";
`]
The parser is essentially a simple list parser. It ignores all whitespaces. All starting keywords and end keywords are simply added as WORDs.
Curly braces BLOCKs and "=>" are the only other recognized elements.
The interpretation of the parsed elements list is handled by the following main mapping. It expects repetitions of sequences starting
with one of the starting tokens, then an repetition of * elements not equal to the END token, and finally the keyword "end" (having the END token).
Using a switch statement we trigger three other mappings to handle the elements of the sequences. The code of the mapping is a little more
complex than need be, because Fowler's syntax allows transitions between states to be defined before the states have been defined. So we must
collect all state transition definitions until the end of the mapping, so that we can be sure all states are instantiated, before
instantiating the transitions.
DSL::DSLMapping create MainMapping -mapping {
@rep * {
@seq {
@elt id {$id == "events" || $id == "resetEvents" ||
$id == "commands" || $id == "state"}
@rep * {
@elt e {$e != "end"} {append body $e}
} {set body ""} {
switch $id {
events {
KeyCodeBlockMapping map $body "set class Event"
}
resetEvents {
ResetEventsBlockMapping map $body
}
commands {
KeyCodeBlockMapping map $body "set class Command"
}
state {
set transitionCode [string append $transitionCode "\n"
[StateBlockMapping map $body "set smObj $smObj"]]
}
}
}
@elt end {$end == "end"}
}
} {set transitionCode ""} {
eval $transitionCode
}
}
The mappings for Event, Command, and ResetEvents are rather trivial and could be realized with a simple foreach loop
as well. We realize them as mappings only to illustrate the concept further. The mapping for State is a little more interesting, but
also simple:
DSL::DSLMapping create KeyCodeBlockMapping -mapping {
@rep * {
@seq {
@elt key
@elt code
} {} {
$class create $key -code $code
}
}
}
DSL::DSLMapping create ResetEventsBlockMapping -mapping {
@rep * {
@seq {
@elt event {} {
if {![interp isObject $event] || ![$event isType Event]} {
throw [ErrorException create -msg "object $event is not an event"]
}
$event isResetting true
}
}
}
}
DSL::DSLMapping create StateBlockMapping -mapping {
@seq {
@elt ID {} {
State create $ID
}
@rep 0..1 {
@seq {
@elt actionsKeyword {$actionsKeyword == "actions"}
@elt actionsList {} {
$ID actions $actionsList
}
}
}
@rep * {
@seq {
@elt trigger
@elt arrowKeyword {$arrowKeyword == "=>"}
@elt nextState
} {} {
set transitionCode [string append $transitionCode "\n"
"Transition create -trigger $trigger -source $ID -target $nextState"]
}
} {}
} {
set transitionCode ""
$smObj set states ""
} {
$smObj append states $ID
get transitionCode
}
}
Finally, we need to stitch all the parts together. To ease this, we define an object to represent the DSL:
Object create SmDSL -classes SmDSL
SmDSL method readFile {name} {
set file [File create -name $name]
return [$file read]
}
SmDSL method mapFile {smObjName file} {
puts "... ... $file"
set code [SmDSL readFile $file]
set smObj [StateMachine create $smObjName]
set parsedCode [statemachineParser apply $code]
MainMapping map $parsedCode "set smObj $smObj"
return $smObj
}
Now we can define a Run.frag script to run the DSL, which essential invokes the mapFile method:
SmDSL mapFile missGrantsStateMachine "./input/missGrants.sm"
In this example we can see the main benefits of external DSLs in Frag. We can provide a custom syntax, check all elements
semantically either during the mapping or in later stages of working with the models, and provide custom error messages
that are useful for the DSL user. Hence, we can provide a much saver and easier way to use DSLs for non-technical stakeholders
than with the embedded DSL approach. The benefit of the rule-based parsing approach in this example is that it is easy to change
parse rules and mappings, custom error messages can easily be embedded, and mappings can be directed to different language models.
The standard imperative programming model can be used and standard debugging techniques are applicable.
As explained before the Frag interpreter communicates with the user using Duals. That means,
Frag internally uses a structure, called Duals, for representing all words in the language.
Each Dual has two representations: the string representation shown to the user of the language and an internal implementation. The
Dual are created during parsing. That is, each element of the parsed elements list - both for the Frag internal parser and
user-defined parsers - are Duals.
Sometimes it is handy to look into Duals to understand their type or token when debugging parsers and mappings.
Frag offers the dual command to do this. dual offers a number of methods explained below.
The method getType has the syntax:
dual getType <dual>
It allows you to determine the type of a dual. For example, you can print the type of a number of duals:
set s "a b c"
set o [Object create]
puts "[dual getType $s] [dual getType $o]"
This will print "StringValue FragObject".
getToken allows you to print the token of a dual. Its syntax is:
dual getToken <dual>
For example, the following code defines a small parser and parses a text. There
are tokens for whitespaces (WS) and non-whitespaces (NWS). We print a list of
all tokens. The result is for the small parsed text is: "WS WS NWS NWS NWS WS WS WS NWS".
LexicalParsing::Parser create p
p setRules `
WS = { \t\n\r};
% WS "WS";
% (!WS)[1..*] "NWS";
`
set result [p apply "\n\t123\r\n\te"]
set l ""
foreach i $result {
append l [dual getToken $i]
}
puts [get l]
getPosition return the position of the dual in the source code in which it was parsed. If the
dual has not been created by parsing, the default value 0 is returned.
The syntax is:
dual getPosition <dual>
For example the following code prints the positions of the words in "a b c d", i.e., it prints "0 2 4 6".
LexicalParsing::Parser create parser1
parser1 setRules `
WS = { \t\n\r};
%- WS;
% (!WS)[1..*] "WORD";
`
set result [parser1 apply "a b c d"]
set l ""
foreach d $result {
append l [dual getPosition $d]
}
puts [get l]
getLine return the line number of the dual in the source code in which it was parsed. If the
dual has not been created by parsing, the default value 0 is returned.
The syntax is:
dual getLine <dual>
For example the following code prints the positions of the words in a parsed string, i.e., it prints "2 3 4 5".
LexicalParsing::Parser create parser1
parser1 setRules `
WS = { \t\n\r};
%- WS;
% (!WS)[1..*] "WORD";
`
set result [parser1 apply "
a
b
c
d
"]
set l ""
foreach d $result {
append l [dual getLine $d]
}
puts [get l]
